

I love that this mirrors the experience of experts on social media like reddit, which was used for training chatgpt…
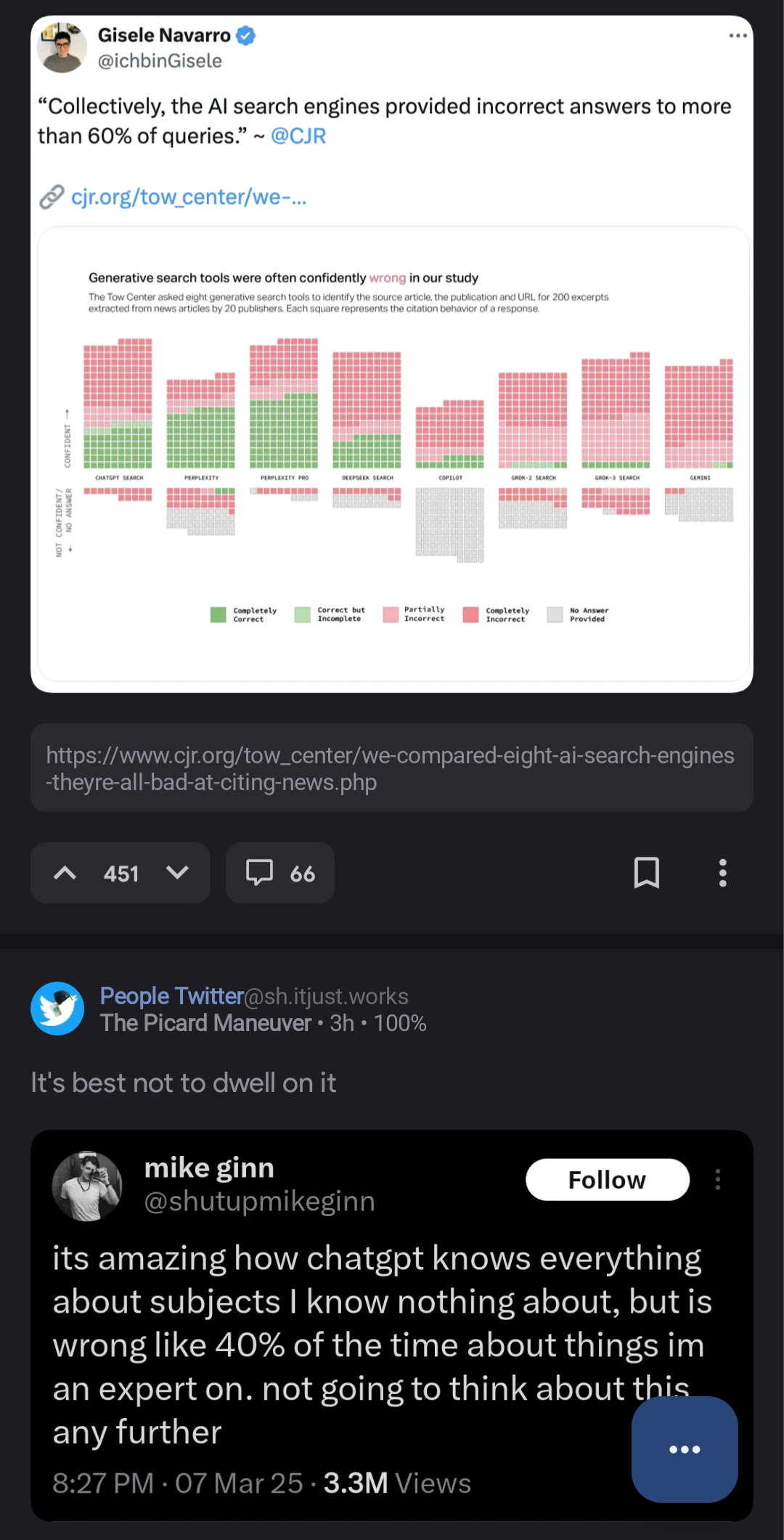
First off, the beauty of these two posts being beside each other is palpable.
Second, as you can see on the picture, it’s more like 60%
No it’s not. If you actually read the study, it’s about AI search engines correctly finding and citing the source of a given quote, not general correctness, and not just the plain model
Read the study? Why would i do that when there’s an infographic right there?
(thank you for the clarification, i actually appreciate it)
deleted by creator
Well yes but also no. Every text will be potentially wrong because authors tend to incorporate their subjectivity in their work. It is only through inter-subjectivity that we can get closer to objectivity. How do we do that ? By making our claims open to scrutiny of others, such as by citing sources, publishing reproducible code and making available the data we gathered on which we base our claims. Then others can understand how we came to the claim and find the empirical and logical errors in our claims and thus formulate very precise criticism. Through this mutual criticism, we, as society, will move ever closer to objectivity. This is true for every text with the goal of formulating knowledge instead of just stating opinions.
However one can safely say that Chatgpt is designed way worse then Wikipedia, when it comes to creating knowledge. Why ? Because Chatgpt is non-reproducible. Every answer is generated differently. The erroneous claim you read in a field you know nothing about may not appear when a specialist in that field asks the same question. This makes errors far more difficult to catch and thus they “live” for far longer in your mind.
Secondly, Wikipedia is designed around the principle of open contribution. Every error that is discovered by a specialist, can be directly corrected. Sure it might take more time then you expected until your correction will be published. On the side of Chatgpt however there is no such mechanism what so ever. Read an erroneous claim? Well just suck it up, and live with the ambiguity that it may or may not be spread.
So if you catch errors in Wikipedia. Go correct them, instead of complaining that there are errors. Duh, we know. But an incredible amount of Wikipedia consists not of erroneous claims but of knowledge open to the entire world and we can be gratefull every day it exists.
Go read “Popper, Karl Raimund. 1980. „Die Logik der Sozialwissenschaften“. S. 103–23 in Der Positivismusstreit in der deutschen Soziologie, Sammlung Luchterhand. Darmstadt Neuwied: Luchterhand.” if you are interested in the topic
Sorry if this was formulated a little aggressively. I have no personal animosity against you. I just think it is important to stress that while yes, both may have their flaws, Chatgpt and Wikipedia. Wikipedia is non the less way better designed when it comes to spreading knowledge then Chatgpt, precisely because of the way it handles erroneous claims.
I feel this hard with the New York Times.
99% of the time, I feel like it covers subjects adequately. It might be a bit further right than me, but for a general US source, I feel it’s rather representative.
Then they write a story about something happening to low income US people, and it’s just social and logical salad. They report, it appears as though they analytically look at data, instead of talking to people. Statisticians will tell you, and this is subtle: conclusions made at one level of detail cannot be generalized to another level of detail. Looking at data without talking with people is fallacious for social issues. The NYT needs to understand this, but meanwhile they are horrifically insensitive bordering on destructive at times.
“The jackboot only jumps down on people standing up”
- Hozier, “Jackboot Jump”
Then I read the next story and I take it as credible without much critical thought or evidence. Bias is strange.
Can you give me an example of conclusions on one level of detail can’t be generalised to another level? I can’t quite understand it
Perhaps the textbook example is the Simpson’s Paradox.
This article goes through a couple cases where naively and statically conclusions are supported, but when you correctly separate the data, those conclusions reverse themselves.
Another relevant issue is Aggregation Bias. This article has an example where conclusions about a population hold inversely with individuals of that population.
And the last one I can think of is MAUP, which deals with the fact that statistics are very sensitive in whatever process is used to divvy up a space. This is commonly referenced in spatial statistics but has more broad implications I believe.
This is not to say that you can never generalize, and indeed, often a big goal of statistics is to answer questions about populations using only information from a subset of individuals in that population.
All Models Are Wrong, Some are Useful
- George Box
The argument I was making is that the NYT will authoritatively make conclusions without taking into account the individual, looking only at the population level, and not only is that oftentimes dubious, sometimes it’s actively detrimental. They don’t seem to me to prove their due diligence in mitigating the risk that comes with such dubious assumptions, hence the cynic in me left that Hozier quote.



{kind=link}