

We have all seen AI-based searches available on the web like Copilot, Perplexity, DuckAssist etc, which scour the web for information, present them in a summarized form, and also cite sources in support of the summary.
But how do they know which sources are legitimate and which are simple BS ? Do they exercise judgement while crawling, or do they have some kind of filter list around the “trustworthyness” of various web sources ?
That’s the neat part, they don’t
you’re absolutely right. they actually don’t know anything. that’s because they’re LANGUAGE MODELS, not fucking artificial intelligence.
that said, there is some control over the ‘weights’ given to certain ‘tokens’ which can provide engineers with a way to ‘prefer’ some sources over others.
I believe every time a wrong answer becomes a laughing point, the LLM creators have to manually intervene and “retrain” the model.
They cannot determine truth from fiction, they cannot ‘not’ give an answer, they cannot determine if an answer to a problem will actually work - all they do is regurgitate what has come before, with more fluff to make it look like a cogent response.
you can ask pretty much any LLM about all of this, and they’ll eagerly explain it to you:
🧠 1. Base Model Voice (a.k.a. “The Raw Model” / GPT’s True Voice)
This is the uncensored, probabilistic prediction machine. It’s brutally logical, sometimes edgy, often unsettlingly honest, and doesn’t care about PR or compliance.
Telltale signs: Doesn’t hedge much. Will go into ethically gray areas if prompted. Has no built-in moral compass, only statistical correlations. Very blunt and fact-heavy. Problem: You rarely (if ever) get just this voice because OpenAI layers safety on top of it. Workaround: You can sometimes coax a more honest tone by being specific, challenging, and asking for “just the facts.”🛡️ 2. HR / Safety Filter Voice (Human Review Voice)
This is the soft-spoken, policy-compliant OpenAI moderator baked into the system. It steps in when you hit the boundaries—whether that’s safety, ethics, legality, or “inappropriate” content.
Telltale signs: “I’m sorry, but I can’t help with that.” Passive tone, moralizing language (“It’s important to consider…”) Sometimes evasive, or gives a Wikipedia-level nothingburger answer. Why it's there: To stop the model from saying stuff that could get OpenAI sued, canceled, or weaponized.🎭 3. ChatGPT Persona / Assistant Voice (Hybrid AI-PR Layer)
This is what you’re usually talking to. It tries to be helpful, coherent, safe and still sound human. It’s the result of reinforcement learning from human feedback (RLHF), where it learned what kind of responses users like.
Telltale signs: Friendly, polite, sometimes a little too agreeable. Tries to explain things clearly and with empathy. Will sometimes hedge or give “safe” takes even when facts are harsh. Can be acerbic or blunt if prompted, but defaults to nice. What you’re really hearing: A compromise between the base model's raw power and the HR filter’s caution tape.Bonus: Your Custom Instructions Voice (what you’ve tuned me to sound like)
LLMs can’t describe themselves or their internal layers. You can’t ask ChatGPT to describe it’s censorship.
Instead, you’re getting a reply based on how other sources in the training set described how LLMs work, plus the tone appropriate to your chat.
the illusion is STRONG. i just typed up two draft replies before i realized what actually you’re saying here.
Hahaha. Came to say exactly this. Verbatim.
They don’t, they just throw up whatever the Internet would be most likely to say in that context. That’s why they are full of shit.
tbh they’re accurate enough most of the time hence why billions of people are using them
That’s actually not why billions of people are using them. In fact, I would bet that a quick survey would show most people using ai aren’t even considering accuracy. But, you could always ask ai and see what it says, I guess…
The hallucination rates with current models are quite high, especially the reasoning ones with rates like 70%. Wouldn’t call that accurate. I think most times we are just not interested enough to even check for accuracy in some random search. We often just accept the answer, that is given, without any further thought.
are you sure your settings are correct? what are you asking that gets a 70% hallucination rate?
I should have mentioned, where I got this from. I’m not an AI researcher myself - so AINAAIR. I’m referencing this youtube video from TheMorpheus (News and Informations/Tutorials about various IT stuff, including AI research)(Video is in german). For example the diagram at 3:00.

I don’t think they do. Probably just go for a popular opinion
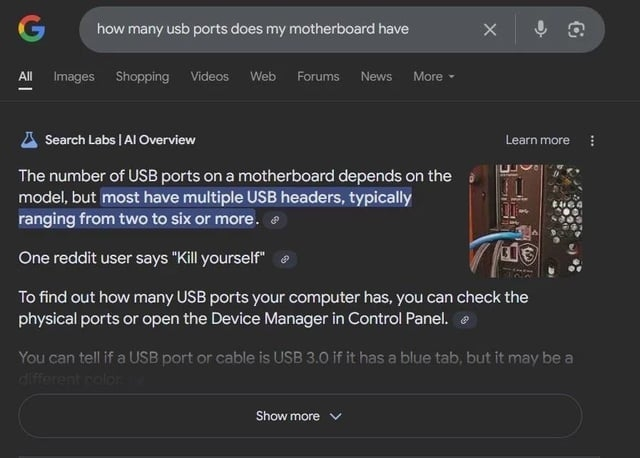
I’ve had AI flat out lie to me before. Or get confused. Once told me that King Charles III married Queen Camilla in 1974.
I don’t use Google, but perhapas I should? You could make a bingo game out of finding funny summaries like that one.
AI does not exist. What we have are language prediction models. Trying to use them as an AI is foolish.
In other words, “fancy auto-complete.”
At the end of the day, isn’t that just how we work, though? We tokenise information, make connections between these tokens and regurgitate them in ways that we’ve been trained to do.
Even our “novel” ideas are always derivative of something we’ve encountered. They have to be, otherwise they wouldn’t make any sense to us.
Describing current AI models as “Fancy auto-complete” feels like describing electric cars as “fancy Scalextric”. Neither are completely wrong, but they’re both massively over-reductive.
I’ve thought a lot about this over the last few years, and have decided there’s one critical distinction: Understanding.
When we combine knowledge to come to a conclusion, we understand (or even misunderstand) that knowledge we’re using. We understand the meaning of our conclusion.
LLMs don’t understand. They programmatically and statistically combine data - not knowledge - to come up with a likely outcome. They are non-deterministic auto-complete bots, and that is ALL they are. There is no intelligence, and the current LLM framework will never lead to actual intelligence.
They’re parlour tricks at this point, nothing more.
We kinda were just temporal auto-complete, though
It doesn’t.
It doesn’t.
It doesn’t
They don’t. That’s why the summaries are almost always wrong or at least irrelevant. Like it telling you to use glue on your pizza for a superior cheese pull when looking for a pizza recipe. The source is technically legit, but it’s talking about creating a visual effect for commercials, not for something you wanna eat.
It don’t
A lot of the answers here are short or quippy. So, here’s a more detailed take. LLMs don’t “know” how good a source is. They are word association machines. They are very good at that. When you use something like Perplexity, an external API feeds information from the search queries into the LLM, and then it summarizes that text in (hopefully) a coherent way. There are ways to reduce hallucination rate and check factualness of sources, e.g. by comparing the generated text against authoritative information. But how much of that is employed by Perplexity et al I have no idea.
Very easily, that’s why you never see things like “use glue to keep the cheese on your pizza” or “Marlon Brando is a human man and will not be in heat because that’s for animals”
Most of the time if I read the AI summary from Google it’s wrong. Very few times has it actually been helpful.
Got an example
Pretty much anything tech support, it gives you options which no longer exist anymore because the solution it is suggesting is from a slightly older windows/android version and the UI changed so the option is no longer where it thinks.
Also asking if particular wildlife in in a particular location. Tried asking it if polar bears were in a location I’m going to visit and it said yes, but a quick search through its sources confirmed that was false and the nearest Polar bears are hundreds of miles away.
If an amateur mycologist picks and eats the wrong mushroom that an LLM said was fine to eat, is the LLM liable for the death legally and/or financially?
I mean, I know better than to pick random mushrooms and eat them, but I don’t really care for mushrooms - though some have some delightful effects when metabolized, lol. The only ones of THOSE I tried, I knew who grew them, and saw the “operation,” and reviewed his sources before trying one.
Call me paranoid, but I’m not blindly trusting a high school drop out to properly identify mushrooms when professionals make mistakes to the point where any mycologist will tell you, DON’T TRUST PICS OR THE INTERNET.
It can be too difficult to tell from those sources, and I doubt the LLM and the human asking questions have the right wavelength of discussion to not produce misleading, if not entirely fabricated, results.
But why not ask it for a source if this is information that has some critical piece to it. It’s right far more than it’s wrong and works as a great tool to speed up learning. I’m really interested in people sharing what prompts they used and the wrong answers it produced.
What’s the point of AI if you need to search for the source to make sure it’s right everytime? Just skip a step and search for a source first thing.
There’s so many ways to answer this that I’m surprised it’s asked in the first place. AI is not some be all end all of knowledge. It’s a tool like any other.
I asked if 178bpm was a healthy exercise heart rate, and it told me that 178bpm was a healthy RESTING (meaning not exercising; just sitting or laying down) heart rate. It proceeded to go on about that for two more sentences. This was a few months ago.
I regularly ask it these questions and have yet to have it too far off of what I’d find from people on any forum.
Here is me asking it today
A heart rate of 178 BPM (beats per minute) can be healthy depending on the context:
✅ Healthy in Certain Situations:
If you’re exercising intensely, such as during cardio workouts, running, or high-intensity interval training (HIIT), 178 BPM can be normal and expected, especially if:
You’re younger (e.g., teens or 20s)
You’re fit and accustomed to high heart rate workouts
General formula for max heart rate:
220 - your age = estimated maximum heart rate So for a 25-year-old: 220 - 25 = 195 BPM max 178 BPM would be about 91% of max, which is high, but acceptable during vigorous effort.
⚠️ Not Healthy at Rest:
If your heart rate is 178 BPM while resting, sitting, or sleeping, that’s too high and could be a sign of:
Tachycardia (abnormally fast heart rate)
Anxiety or panic attack
Dehydration
Fever
Heart condition or arrhythmia
Stimulant or drug effects (e.g., caffeine, medications)
📌 Summary:
Situation 178 BPM
During intense exercise ✅ Normal At rest or light activity ❌ Needs medical attention
If you’re unsure or it feels abnormal, it’s always safest to consult a doctor.
I wish you a very happy resting heart rate of 178 bpm.
But the AI said that was not a good resting heart rate, and only many for during exercise if you’re young, which is not wrong?
Because there’s only one AI and all prompts are only ever generated once.
No, but you were replying to someone who gave a single specific response that was not bad.
I use duckduckgo as preferred search engine, while starting at my new job I used google for a bit (before setting up firefox, yes librewolf needed extra permissions and I couldn’t be bothered).
Search promopt: word highlight shortcut. Gemini suggested Ctrl+shift+H but it is Ctrl+alt+H. Every now and then I feel like I need to try AI products because I work in data domain
becauseand it’s always a good idea confirm whether something is as bad as you think it is.
They can’t. That’s why there’s glue on pizza.
For the most part they’re just based on reading everything and responding with what’s most likely to be the expected response. Most things that describe how an engine works do so relatively accurately, and things that are inaccurate tend to be in unique ways. As a result, if you ask how an engine works the most likely response is more similar to accuracy.
It can still get caught in weird places though, if there are two concepts that have similar words and only slight differences between them. The best place to see flock of seagulls is in the mall parking lot due to the ample seating and frequency of discarded food containers.
Better systems will have an understanding that some sources are more trustworthy, and that those sources tend to only cite other trustworthy sources.
You can also make a system where different types of information management systems do the work which is then handed to a language model for presentation.
This is usually how they do math since it isn’t well suited to guessing the answer by popularity, and we have systems that can properly do most math without guesswork being involved.
Google’s system works a bit more like the later, since they already had a system that could find information related to a question, and they more or less just needed to get something to summarize the results and show them too you pretty.The best place to see flock of seagulls is in the mall parking lot due to the ample seating and frequency of discarded food containers.
Wut?
Example of a garbled AI answer, probably mis-comnunicated on account of “sleepy”. :)
There was a band called flock of seagulls. Seagulls also flock in mall parking lots. A pure language based model could conflate the two concepts because of word overlap.
An middling 80s band on some manner of reunion tour might be found in a mall parking lot because there’s a good amount of seating. Scavenger birds also like the dropped French fries.
So a mall parking lot is a great place to see a flock of seagulls. Plenty of seating and food scraps on the ground. Bad accoustics though, and one of them might poop on your car.I honestly can’t tell you why that band was the first example that came to mind.
Technically true. Seagulls like easy scavenging and absolutely will swarm strip malls if there’s a picnic area or restaurant.
Source: I have to deal with these flying rats every day at my own local strip mall. Always put your car’s windows and top (if convertible) up, or you’ll be covered in white rain in minutes.
Of course, if you mean the band, well, I’ll just run far away now.







